


复杂环境听不清?奥迪康More两项核心技术让聆听更轻松

问:大脑聆听需要什么?
答:需要声音信号的获取
问:大脑自然聆听需要什么?
答:需要完整声音场景信息的输入
一个完整、精确及平衡的声音场景是大脑自然聆听的最佳条件。听损人士往往需要助听器的协助,来优化声音场景,以便获得更好的聆听体验。
简单来说,助听器对声音的处理过程可以概括为四步:收集→分析→平衡→放大,但如何高水平实现却是一个复杂的问题。到目前为止,传统声音处理系统的设计使用理论模型和人为假设都着重于:如何最好地增强语音和减少背景噪声。减少了声音信息的摄入,也就与大脑的自然聆听背道而驰。

环境中的声音带有动态、复杂和不可预测的特性,在这样的考验下,如何为大脑提供完整视角?

奥迪康More采用了开创性的『AI全声景领航系统』(以下简称“MSI”)和『全声景言语提升技术』(以下简称“MSO”),这两项技术实现了对所有声景的自然分析处理,帮助听损人士享受更加立体的、完整的声音场景,实现声音处理技术的重大飞跃。对于四步声音处理过程,奥迪康More是这样优化的
第1步:全方位收集
MSI利用多声源接入技术将整个空间的全部声源点进行收集,做最基础的分析(判断是言语声还是噪声),24通道下对声音场景进行高速扫描,确保了对不同声源的正确映射。
第2步:精准分析
第3步:声音平衡
在对全部声音点进行收集后,紧接着我们将利用MSI核心子功能DNN对声音进行精准的分析与平衡。
1200万个真实的声音场景的训练确保了More知道的不仅仅是言语与噪声的区别,而是男声与女声、儿童声与老年声、喇叭声与小提琴声的区别以及彼此在此刻的主次、方向、距离……

每个声源独立而又相互联系,DNN帮助More根据学习成果自动化平衡不同声源,创建基于现实的自然声景。
第4步:放大压缩
声音放大压缩技术一直是奥迪康的骄傲,在More上,MSO的放大精度是过去的6倍,也就意味着它能将MSI所创建的完整声景做到精确的声信号放大。而其基于芯片所带来的处理速度确保了用户无缝获得重要的细节体验。
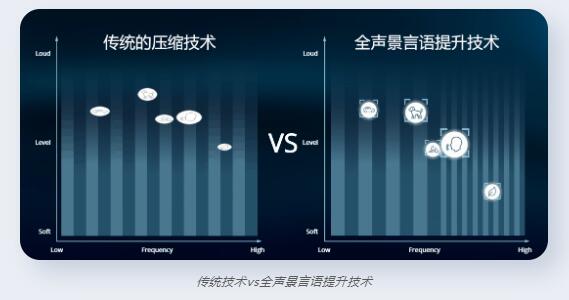
也许有人会问,听觉是主观的,怎么能确保用户得到的是他/她想要的呢?奥迪康也在MSI提供了多种个性化选择,依托于理论依据与用户的主观感受,从聆听难易度、耳廓构型、声源主次多个角度出发,构造属于个体的完美听觉感知。
我们所关注的是
为每一位听力下降用户提供完整声景
为他们的大脑提供完整视角
让用户在复杂和动态环境中
获得更好言语理解,同时降低精力损耗
奥迪康More助听器
支持所有环境下的立体清晰聆听
让现实更真实
文字 / Demant中国培训部 王春晖
文献参考:
• Brændgaard, M. (2020a). MoreSound Intelligence [Tech paper]. Oticon
• Akeroyd M. A. (2014). An overview of the major phenomena of the localization of sound sources by normal-hearing, hearing-impaired, and aided listeners. Trends in hearing, 18, 2331216514560442.
• Brændgaard, M. (2020b). The Polaris Platform. [Tech paper]. Oticon
• Santurette, S., & Behrens, T. (2020). The audiology of Oticon More™ [White paper]. Oticon